
最近、ディープラーニングについて勉強を始めています。
しかし、調べてみると数式が出てきたり・・となかなか手ごわいです。
もっと取っ付き易いものはないかな?と調べているうちに機械学習を利用した画像認識や文字認識に行き当たりました。
画像認識を紹介できればカッコよかったのですが、まだ把握できていないので、今回はJavaでの実装が簡単だった文字認識について紹介したいと思います。
(機械学習の話題を出しておいて恐縮ですが、機械学習要素は無いです)
Javaで文字認識を行うには「Tess4J」というライブラリを使用します。
導入方法
1. 取得
以下のサイトでライブラリをダウンロードします。https://sourceforge.net/projects/tess4j/files/tess4j/3.3.1/
ダウンロードしたzipファイルを解答すると「Tess4J」フォルダがあるはずです。
「Tess4J」フォルダは後から参照を行うのでわかりやすい場所に配置してください。
2. ビルドパスの設定
「Tess4J」フォルダ内の「dist」フォルダと「lib」フォルダがあるのでその中のjarファイルすべてをビルドパスに追加してもらえればOKです。3. ソースコード
public class OCRTest {
public static void main(String[] args) throws IOException, TesseractException {
//画像読み込み
File target = new File("C:\\temp\\moji.jpg");
BufferedImage image = ImageIO.read(target);
//解析
ITesseract tesseract = new Tesseract();
tesseract.setDatapath("C:\\Tess4J\\tessdata");
tesseract.setLanguage("eng");
List wordList = tesseract.getWords(image, TessPageIteratorLevel.RIL_BLOCK);
String str = tesseract.doOCR(image);
//結果出力
System.out.println(wordList);
System.out.println(str);
}
}
「”C:\temp\moji.jpg”」が文字認識の対象となる画像です。下図のペイントで手書きした画像になります。
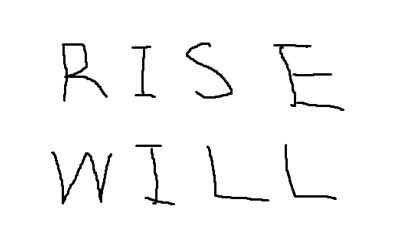 「”C:\Tess4J\tessdata”」は「Tess4J」フォルダ内の設定ファイルとなっています。「Tess4J」フォルダを配置したパスにあわせて設定してください。
「”C:\Tess4J\tessdata”」は「Tess4J」フォルダ内の設定ファイルとなっています。「Tess4J」フォルダを配置したパスにあわせて設定してください。4.実行結果
[RISE
WlLL
[Confidence: 56.706688 Bounding box: 21 17 383 212]]
RISE
WlLL
RISEWILLのロゴでも試してみました。
[RISE
[Confidence: 87.269112 Bounding box: 1 4 81 29]]
RISE
どうも色がグレイスケールじゃないとだめみたいです。
色をグレイスケールにして確認
[RISEéi/ILL
[Confidence: 57.493725 Bounding box: 1 4 162 29]]
RISEéi/ILL
まとめ
以上、Javaによる文字認識でした。「Tesseract-OCR」という「Tess4J」のC++版もあるのですが、そちらでは精度があまりよくないらしい記事を見たので難しいかもしれません。
ただ、「Tesseract-OCR」も「Tess4J」も機械学習によって認識の精度を高めることができるので、いろいろ試してみたいと思います。






